
世上有一条永恒不变的法则.当你不在乎 你就得到;当你变好 你才会遇到更好的,只有当你变强大 你才不害怕孤单,当你不害怕孤单,你才能宁缺毋滥。
人性的第一性原理:别急着处理情绪,先找到它从哪里来
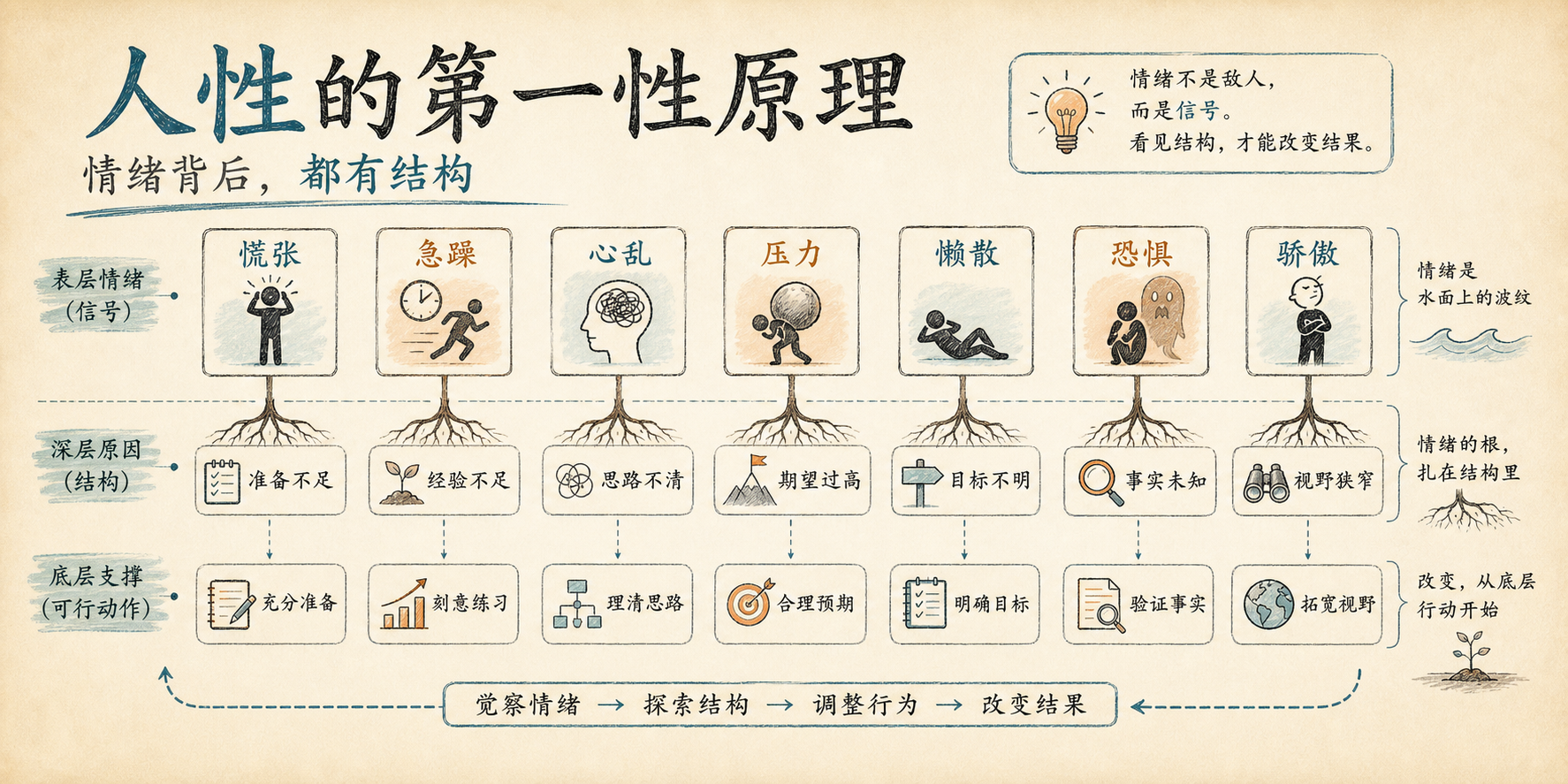
最近看到一张图,标题叫 “人性的第一性原理”。
图里列了 15 种常见状态:慌张、急躁、轻浮、心乱、压力、贪婪、心累、劳苦、懒散、暴躁、恐惧、憎恨、痛苦、烦恼、骄傲。每一种状态后面都给了一个更底层的来源,比如慌张来自准备不足,急躁来自经历不够,心乱来自思路不清,懒散来自目标不明,骄傲来自目光短浅。
这张图有点像鸡汤,但我觉得它并不只是鸡汤。
它真正有价值的地方,不是告诉我们“你不应该慌张”“你不应该懒散”“你不应该痛苦”,而是提供了一个更有用的观察角度:
很多情绪本身不是问题,它只是底层结构出了问题之后浮到表面的信号。
皮查伊没多聊 AI,但这三个判断更值得记住

今天刷到 Vincent Logic 转的一条 X 视频,内容是谷歌 CEO 皮查伊在斯坦福毕业典礼上的一段演讲。原帖 的转述很有意思:他几乎没怎么聊 AI,反而讲了一个自己大学时逃课去拉斯维加斯的故事。
这反而让我更愿意把视频看完。
因为在 2026 年,任何一个科技公司 CEO 站上讲台,如果只是再讲一遍“AI 正在改变世界”,其实已经没有太多信息量了。真正有意思的是:当一个身处 AI 风暴中心的人回头看自己几十年的职业判断时,他到底觉得什么最重要。
别把《经济学人》封面当预言书,它更像趋势压缩包

今天读到 Huan 在 X 上那篇关于 《经济学人》2026 封面解读的长文。它把整张封面读成一座“12 个月时钟”,再把 AI、大国竞争、债务压力、卫星与信息控制这些元素,一层一层拆成趋势线索。
我读完之后最大的感受不是“这封面也太会预言了”,而是另一件事:
别把这种封面当预言书,它更像一份高密度的趋势压缩包。
AI时代公司的新护城河:不是模型,而是学习回路
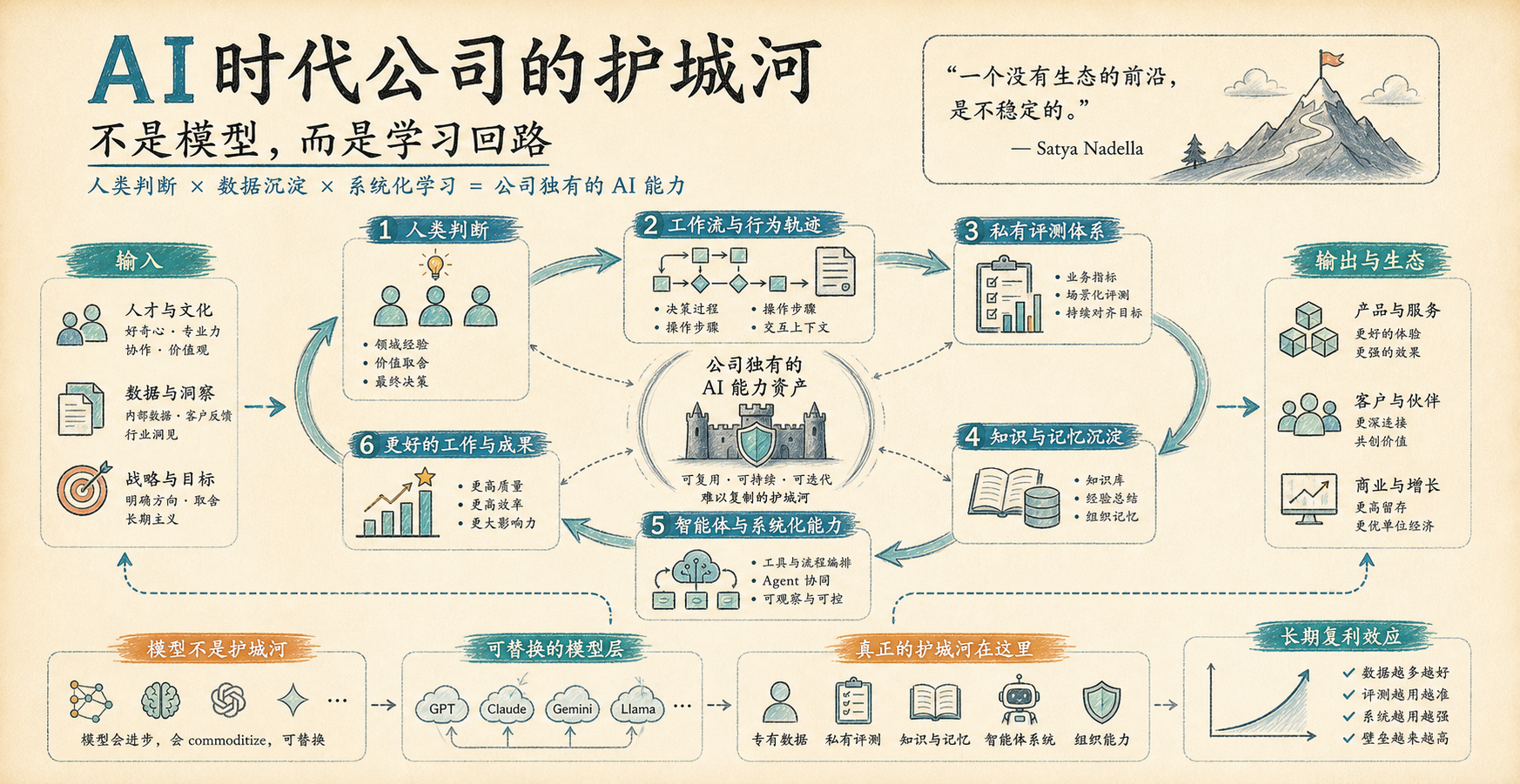
昨天看到 Satya Nadella 在 X 上发的一篇长文:A frontier without an ecosystem is not stable。这篇文章表面上是在谈 AI 时代企业应该如何构建自己的能力,但我觉得它真正有价值的地方,不是又提出了一个关于大模型的判断,而是把一个更底层的问题说清楚了:
AI 时代,公司的核心资产不会只是“用了哪个模型”,而是能不能把自己的经验、流程、判断和组织记忆,变成一套持续变强的学习系统。
这件事如果说得更直白一点,就是:未来企业之间的差距,不只取决于谁接入了更强的模型,而取决于谁能把模型放进自己的业务循环里,让每一次使用都留下可复用的知识、信号和改进。
随机森林算法:用“周末吃饭投票”讲清楚它为什么靠谱
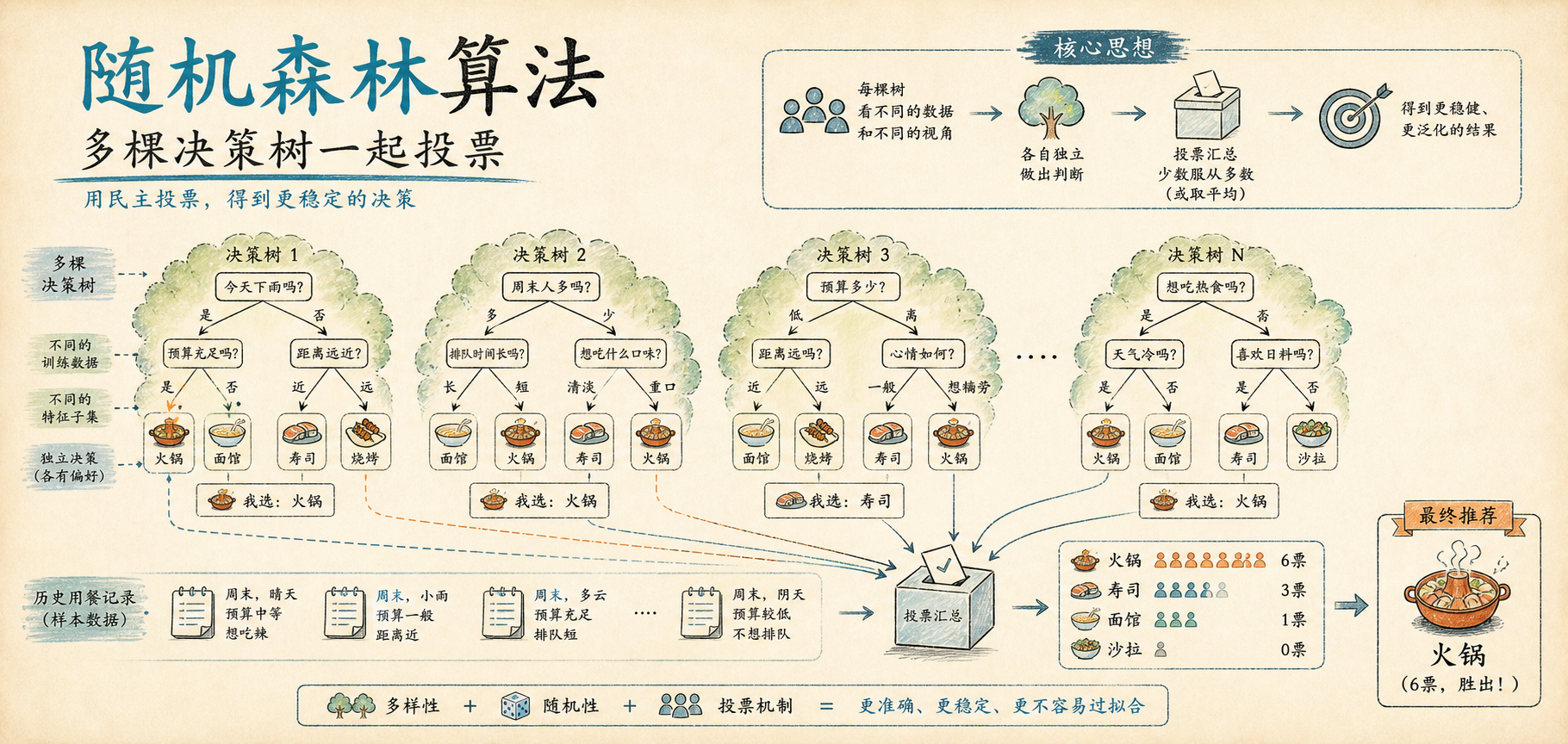
随机森林这个名字,第一次听起来很像一个很硬的机器学习概念。森林、随机、算法,几个词放在一起,很容易让人以为它背后一定有一大堆数学公式。
但如果用通俗的话讲,随机森林其实没有那么神秘。它做的事情很像我们生活里经常用的一种决策方式:
不要只听一个人的意见,多问几个人,然后看多数人怎么选。
为了把这件事讲清楚,我们可以用一个很生活化的问题来类比:周末晚上到底去哪儿吃饭?
Andrej Karpathy Skills:把 AI 编程从“会写代码”拉回到“会做工程”
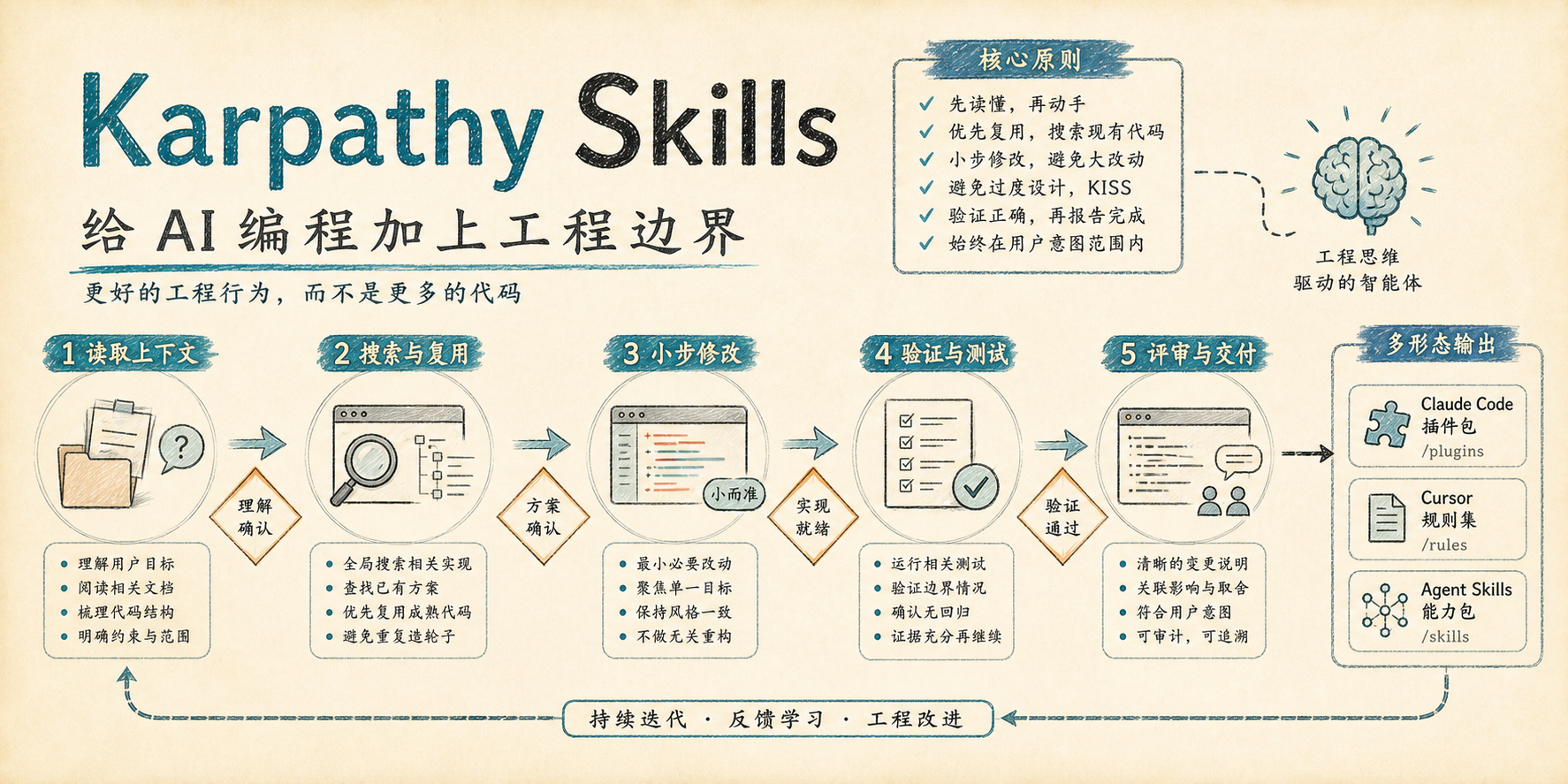
最近看到一个很有意思的仓库:multica-ai/andrej-karpathy-skills。它看起来不像传统意义上的代码库,也不像一个可以直接运行的工具。里面没有复杂框架,没有业务代码,也没有什么炫目的工程实现。它更像是一组给 AI 编程助手准备的“行为准则包”。
但也正因为这样,我反而觉得它挺值得单独写一写。
很多 AI 编程工具现在都在强调更强的模型、更大的上下文、更快的代码生成。但这个仓库关注的方向刚好相反:它不是继续放大 AI 的生成能力,而是试图约束 AI 在工程现场里的行为方式。说得直白一点,它解决的不是“AI 能不能写代码”,而是“AI 写代码时能不能别太自信、别乱扩张、别跳过验证”。
从 Claude Code 看 Multi-Agent 怎么构建
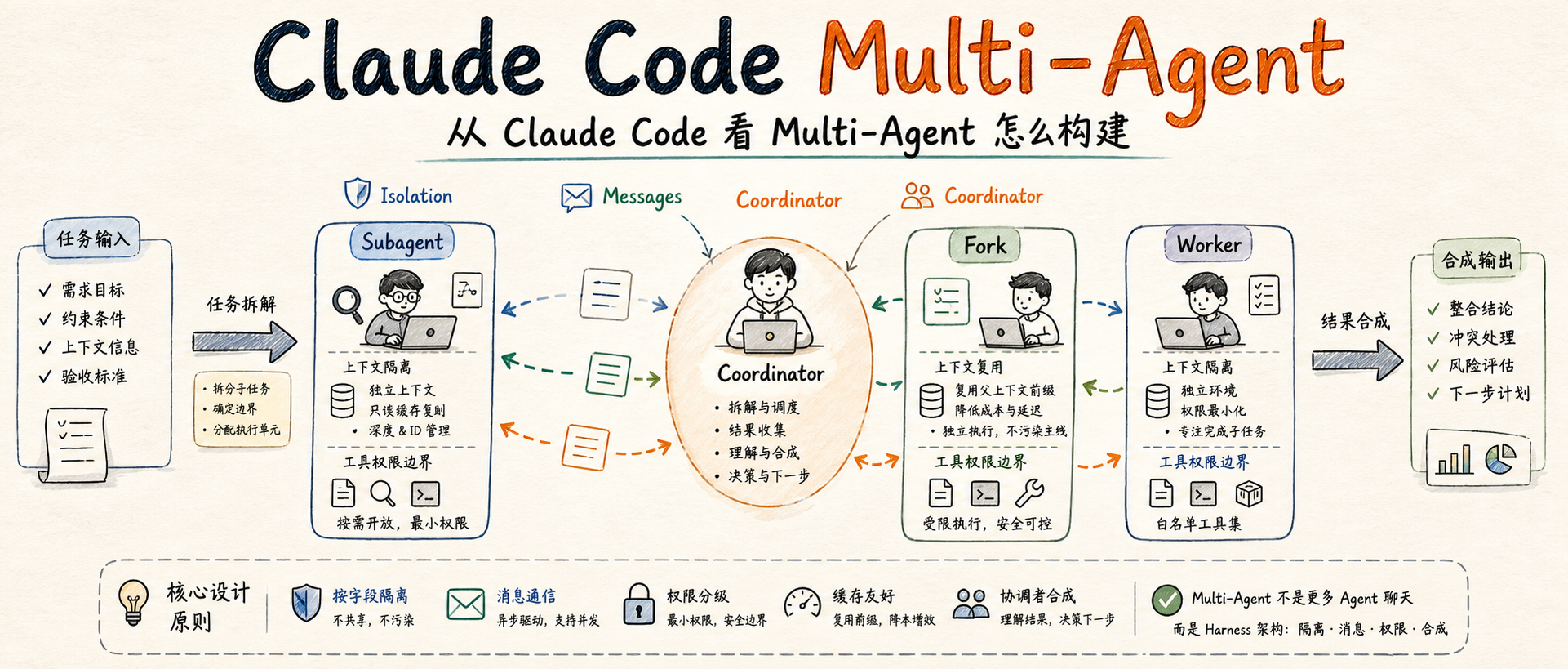
最近读到小林coding那篇关于 Claude Code 多 Agent 实现机制 的文章。原文讲了三个关键机制:常规 Subagent、Fork Subagent 和 Coordinator 模式。
我读完之后更关心的是另一个问题:如果我们自己要构建一个 Multi-Agent 系统,应该从哪里下手?
我的结论是:Multi-Agent 不是“多放几个 Agent 互相聊天”,而是 Harness 在运行时创建多个隔离的执行单元,并用消息、权限和协调者把它们收敛起来。
Multi-Agent 不该被神化:真正重要的是上下文隔离
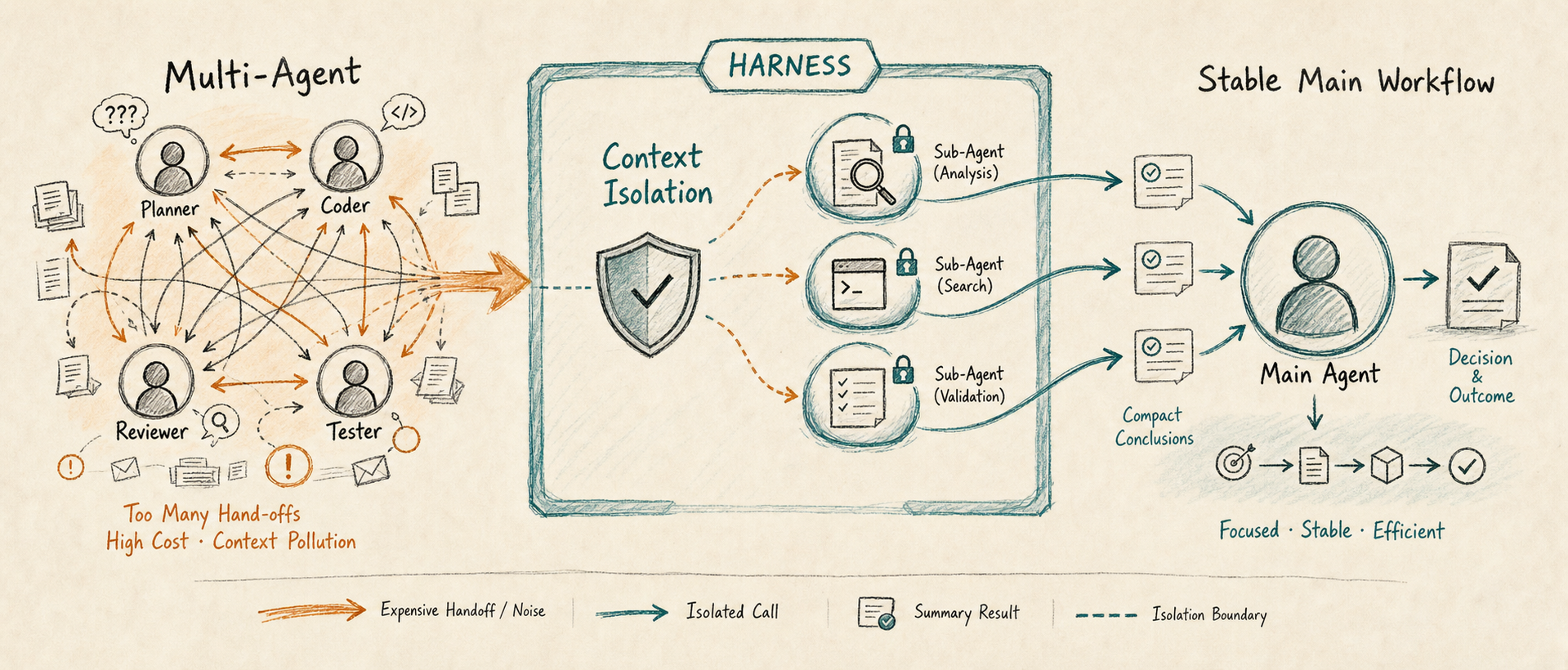
最近看了一篇关于 Harness 工程的分享,文章表面上在讲怎么把 LLM Agent 的 prompt cache 命中率做到 90%+,但我读完之后更在意的,其实是它对 Multi-Agent 的一个反向提醒:
Multi-Agent 不应该被理解成“多几个角色就更智能”,它真正值得保留的价值,是上下文隔离和工程边界。
这件事很有意思。过去一年,大家谈 Agent 时很容易自然滑向 Multi-Agent:一个 Planner,一个 Coder,一个 Reviewer,一个 Tester,再加一个 Manager 做调度。这个结构看起来很像真实团队,也很符合人类对协作的直觉。但问题在于,模型不是人。把人类组织结构照搬到模型运行时里,未必会得到更好的系统,反而可能得到更高的成本、更长的链路和更多上下文损耗。
AI Agent 和 Harness:能力内核与工程护栏
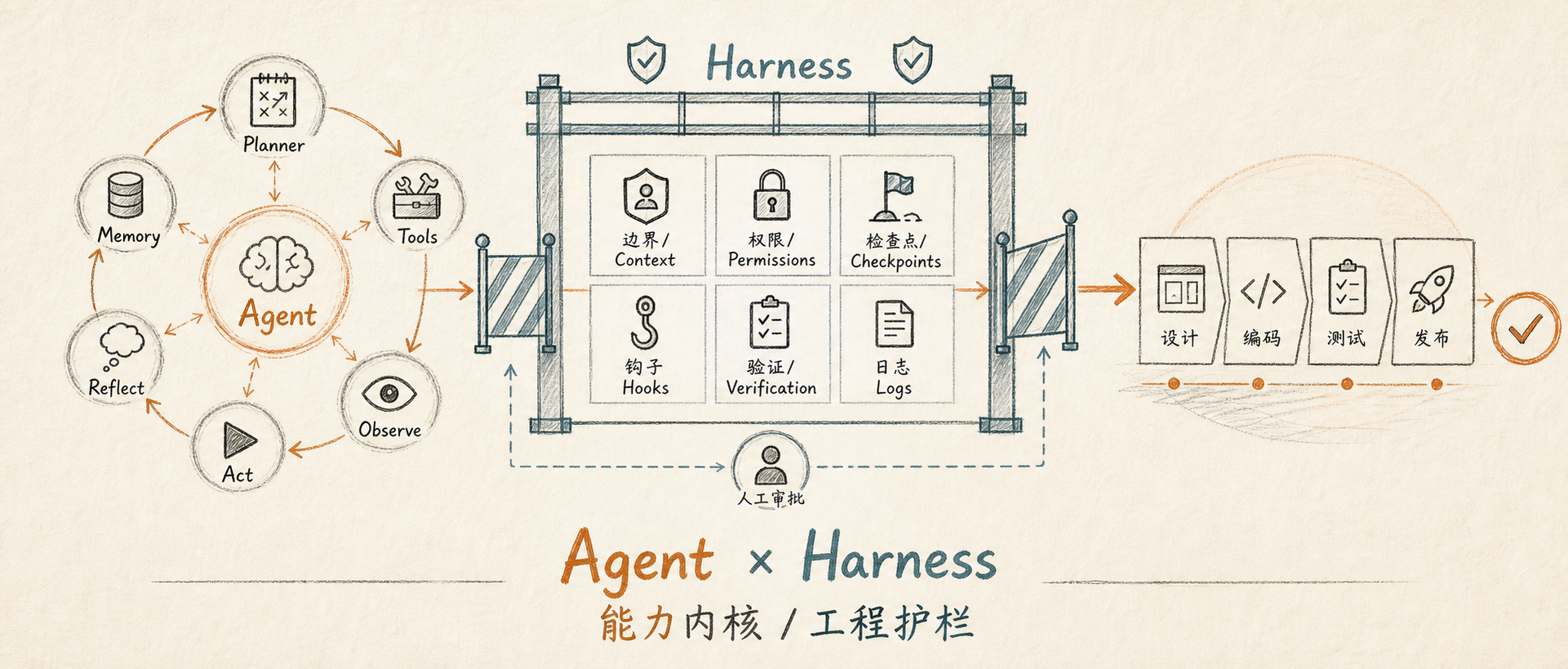
最近聊 AI 编程时,我发现一个很容易混在一起的问题:大家会同时提到 Agent 和 Harness,但很多时候并没有把这两个东西放在正确的位置上理解。
Agent 听起来像是主角,因为它能理解目标、拆任务、调用工具、读写文件、跑命令,甚至根据反馈自己调整下一步。Harness 听起来更像配角,因为它不直接“干活”,而是提供规则、流程、权限、上下文和校验。但如果真要把 AI 放进工程体系里,这两个概念其实缺一不可。
我自己的理解是:Agent 是能力内核,Harness 是工程护栏。Agent 决定 AI 能不能动起来,Harness 决定它能不能在正确的轨道上动起来。