最近看了一篇关于 Harness 工程的分享,文章表面上在讲怎么把 LLM Agent 的 prompt cache 命中率做到 90%+,但我读完之后更在意的,其实是它对 Multi-Agent 的一个反向提醒:
Multi-Agent 不应该被理解成“多几个角色就更智能”,它真正值得保留的价值,是上下文隔离和工程边界。
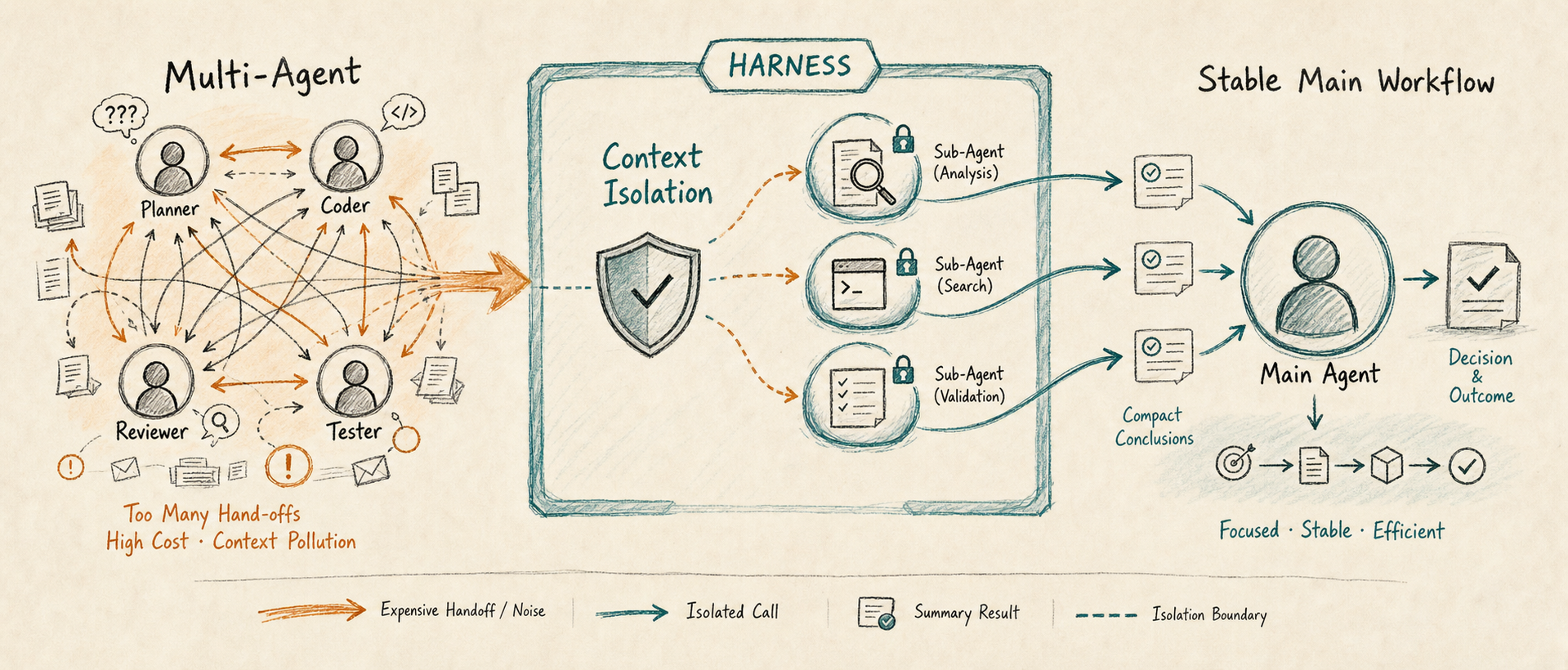
这件事很有意思。过去一年,大家谈 Agent 时很容易自然滑向 Multi-Agent:一个 Planner,一个 Coder,一个 Reviewer,一个 Tester,再加一个 Manager 做调度。这个结构看起来很像真实团队,也很符合人类对协作的直觉。但问题在于,模型不是人。把人类组织结构照搬到模型运行时里,未必会得到更好的系统,反而可能得到更高的成本、更长的链路和更多上下文损耗。
先说结论:Multi-Agent 不是默认更高级
很多人喜欢 Multi-Agent,是因为它看起来更“体系化”。
单 Agent 像一个人在闷头干活,Multi-Agent 则像一个团队:有人规划,有人执行,有人测试,有人评审。直觉上,这当然更可靠。
但 Agent 系统的关键矛盾,和人类团队不一样。
人类分工的前提是:每个人的大脑独立存在,沟通成本虽然高,但每个人可以长期保留自己的经验、判断和上下文。模型不是这样。每个 Agent 背后本质上都是一次或多次 LLM 调用,而每次调用都要面对 prompt、history、tool schema、上下文窗口、cache 命中率这些工程问题。
所以 Multi-Agent 一旦拆得太细,就会出现几个很现实的代价:
- 每个 Agent 都需要自己的 system prompt
- 每次交接都要序列化状态
- 每个角色看到的上下文都不完全一样
- 中间过程会不断膨胀 history
- cache 很容易因为前缀变化而失效
- 最终还需要一个额外步骤把多个结果重新收敛
这不是“协作变复杂”这么简单,而是每一次拆分都会变成真实成本。
原文里提到一个很刺耳的经验:Planner / Coder / Reviewer / Tester 这种多 Agent 工作流,可能让一个单 Agent 几分钟能完成的任务被拉长到十几分钟,成本也被放大很多。这个结论未必适用于所有场景,但它提醒我们,Multi-Agent 并不是免费抽象。
为什么人类分工不能直接照搬给 AI
很多 Multi-Agent 设计有一个潜在假设:既然软件团队可以按角色分工,那么 AI 也可以按角色分工。
但这里忽略了一个差异:人类角色之间的边界,往往是为了降低认知负担;模型角色之间的边界,却可能制造新的上下文损耗。
一个人类 Reviewer 不需要每次 review 都重新加载自己的“评审人格”和“评审工具说明”。他的大脑里本来就有长期经验。模型不是这样。你让一个 Reviewer Agent 出场,就要给它 prompt,给它上下文,给它工具说明,让它读材料,再让它输出判断。然后主 Agent 还要读它的结论,再继续下一步。
这套过程如果没有非常明确的收益,很容易只是把一个任务拆成更多轮调用。
更麻烦的是,角色拆分会让上下文变得碎片化。Planner 看到的问题、Coder 看到的问题、Reviewer 看到的问题并不天然一致。为了让它们一致,就要传递更多状态;为了传递更多状态,就要写更长的消息;消息越长,成本越高,压缩越早到来,cache 越容易被破坏。
所以,Multi-Agent 最大的问题不是“模型会不会协作”,而是:
这种协作结构是否真的减少了系统复杂度,还是只是把复杂度转移到了上下文传递里。
真正有价值的是“隔离”,不是“分工表演”
那是不是 Multi-Agent 就完全没有价值?我觉得不是。
问题不在于“多 Agent”,而在于为什么要多。
如果多 Agent 只是为了模拟一个组织结构:Planner、Coder、Tester、Reviewer 各跑一遍,我会比较警惕。因为这很容易变成一种形式感很强、工程收益不稳定的编排。
但如果多 Agent 是为了做上下文隔离,它就有意义了。
比如代码审查场景。主 Agent 正在做实现,如果让它在同一个 history 里读几十个文件、跑一堆 grep、展开长篇分析,主会话会迅速膨胀。后续每一轮都要背着这些中间过程继续跑,成本和干扰都会变大。
这时候启动一个子 Agent 做只读审查,是合理的。子 Agent 可以在自己的上下文里完成大量探索,最后只把结论返回给主 Agent。主 Agent 不需要保存所有中间细节,只需要看到“发现了什么、建议怎么处理、风险在哪里”。
这和传统 Multi-Agent 编排不一样。
传统编排强调角色分工;这里强调的是状态隔离。前者容易把任务拆碎,后者是在保护主上下文。
所以我更愿意把这类能力叫做:局部子 Agent 调用,而不是宏大的 Multi-Agent 工作流。
Multi-Agent 应该长在 Harness 里
这也回到我最近一直在思考的 Harness。
如果 Agent 是执行能力,那么 Harness 就是让执行能力稳定工作的工程外壳。Multi-Agent 如果要有价值,也应该是 Harness 的一部分,而不是在 Agent 之上再套一个抽象的组织架构。
一个健康的设计应该是:
- 主 Agent 负责保持任务主线
- 子 Agent 只在局部场景出现
- 子 Agent 有明确输入、明确输出和明确退出点
- 中间探索尽量不污染主会话
- 返回结果必须被主 Agent 或人工重新判断
这样的 Multi-Agent 是克制的。它不是为了“看起来像团队”,而是为了让任务边界更清楚。
比如下面这些场景,我觉得适合子 Agent:
- 大范围代码审查
- 独立安全风险扫描
- 文档资料压缩
- 多方案并行比较
- 复杂问题的反方审视
- 对某个子目录或子系统做局部分析
它们有一个共同点:中间过程很多,但最终只需要一个高质量结论。把这些过程隔离出去,能减少主 Agent 的上下文负担。
但下面这些场景,我会慎用 Multi-Agent:
- 简单功能开发
- 小范围 bugfix
- 明确步骤的机械修改
- 只是为了套 Planner / Coder / Reviewer 模板
- 没有明确收敛规则的开放讨论
因为这些任务本来就不需要复杂编排。强行拆开,只会增加交接成本。
Prompt Cache 其实暴露了架构问题
原文从 prompt cache 角度切入,这一点很有启发。
很多人会把 cache 命中率当成成本优化问题。但我觉得它更深层的意义是:它暴露了 Agent 架构是否稳定。
如果一个系统动不动就改 system prompt,动不动就换工具 schema,动不动就把动态信息塞进稳定前缀,那么 cache 命中率低只是表象。真正的问题是:系统边界不清楚,稳定信息和动态信息没有分层。
Multi-Agent 也是一样。
如果每个 Agent 都有一套 prompt,每次交接都要重新描述上下文,每个角色都要重新理解任务,那么成本上升只是结果。更底层的问题是:你没有设计好信息应该在哪里稳定、在哪里变化、在哪里隔离、在哪里收敛。
这就是为什么我觉得 Multi-Agent 不能脱离 Harness 来谈。
没有 Harness 的 Multi-Agent,容易变成一堆 Agent 互相传话;有 Harness 的 Multi-Agent,才有机会变成可控的局部能力调用。
对个人和团队的启发
如果要把 Multi-Agent 真正用进日常开发,我觉得可以从几个问题开始,而不是先画角色图。
第一,先问这个任务是否真的需要隔离。
如果只是一个小改动,单 Agent 加清晰上下文就够了。不要为了高级感而拆角色。
第二,问子 Agent 的输出能不能被压缩成稳定结果。
如果一个子 Agent 跑完之后,主 Agent 还必须接收它的大量中间过程,那隔离价值就被抵消了。
第三,问每个子 Agent 有没有明确退出点。
没有退出点的 Agent 很危险。它会不断探索、不断膨胀上下文,最后把任务变成一个越来越大的黑箱。
第四,问 Harness 能不能兜住失败。
子 Agent 的结论不能自动等于事实。尤其是安全审查、架构建议、性能判断,都应该被主 Agent 或人类重新校验。Multi-Agent 不是为了取消判断,而是为了给判断提供更好的材料。
我的判断:未来不是多 Agent 取代单 Agent,而是 Harness 重新定义 Agent 边界
Multi-Agent 这个方向不会消失,但它会从“角色编排崇拜”里慢慢降温。
真正留下来的,不会是那种把人类团队结构机械复制一遍的系统,而是更克制、更工程化的形态:
- 主会话保持稳定
- 子任务按需隔离
- 工具集尽量稳定
- 动态信息不污染稳定前缀
- 中间过程不长期拖累主上下文
- 结果通过 Harness 收敛和校验
说到底,Multi-Agent 的价值不是“多”,而是“边界”。
如果多个 Agent 只是让系统更乱、更贵、更慢,那它不是架构升级,只是复杂度膨胀。只有当它能隔离状态、降低主上下文污染、改善风险控制、提高结果质量时,Multi-Agent 才是值得引入的工程手段。
所以我现在对 Multi-Agent 的态度更谨慎了:
不要先问要几个 Agent,先问哪些上下文必须隔离。
这个问题问清楚了,Multi-Agent 才不会变成一种漂亮但昂贵的表演,而会变成 Harness 里真正有用的一块工程能力。