最近聊 AI 编程时,我发现一个很容易混在一起的问题:大家会同时提到 Agent 和 Harness,但很多时候并没有把这两个东西放在正确的位置上理解。
Agent 听起来像是主角,因为它能理解目标、拆任务、调用工具、读写文件、跑命令,甚至根据反馈自己调整下一步。Harness 听起来更像配角,因为它不直接“干活”,而是提供规则、流程、权限、上下文和校验。但如果真要把 AI 放进工程体系里,这两个概念其实缺一不可。
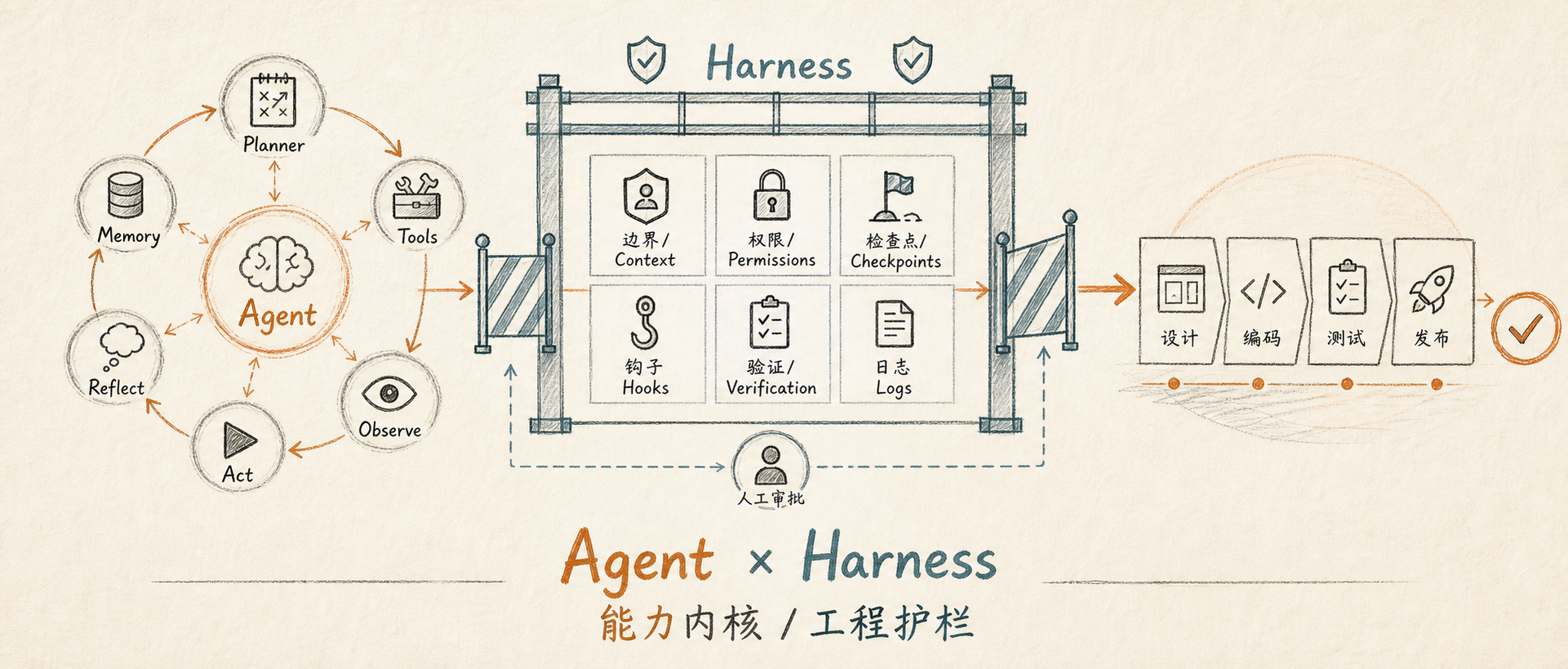
我自己的理解是:Agent 是能力内核,Harness 是工程护栏。Agent 决定 AI 能不能动起来,Harness 决定它能不能在正确的轨道上动起来。
Agent 回答的是“谁来做事”
Agent 的核心不是“会聊天”,而是它具备一个相对完整的行动循环。
一个真正有用的 Agent,至少要能做几件事:
- 理解目标和当前上下文
- 把目标拆成可执行步骤
- 根据步骤选择工具
- 观察工具返回的结果
- 在结果不符合预期时调整计划
- 最后把过程和结果整理出来
所以 Agent 更像一个可以在任务空间里移动的执行单元。它不是一次问答,而是一段连续行动。
这也是为什么 Agent 会让人兴奋。过去我们用 AI,大多是在“问一个问题,拿一个答案”。Agent 出现后,AI 开始像一个能处理任务的人:它会读代码、查文档、改文件、跑测试、再根据失败日志继续修。
但也正因为它能动,风险才被放大了。
一个只会回答问题的模型,最多给你一个错误建议;一个能调用工具的 Agent,如果没有边界,就可能直接把错误建议变成错误改动。
Harness 回答的是“怎么允许它做事”
Harness 这个词如果直译,会有“束具”“安全带”“装备系统”的意思。放到 AI 工程里,我觉得它的含义很贴切:它不是限制 Agent 的价值,而是让 Agent 的价值可以被安全地释放出来。
一个好的 Harness,通常会包含这些东西:
- 明确的任务入口
- 可控的上下文注入
- 工具调用权限
- 高风险路径保护
- 过程产物留痕
- 测试和校验步骤
- 人工确认节点
- 失败后的回退或中止机制
如果说 Agent 是“会开车的人”,Harness 就是道路、护栏、红绿灯、仪表盘和刹车系统。
这套东西看起来没有 Agent 那么智能,但它决定了一个很现实的问题:当 Agent 判断错了,系统能不能拦住它。
这也是 AI 编程进入真实项目后最关键的变化。我们不再只是问“模型能力够不够强”,还要问“它出错时,工程系统有没有兜底”。
为什么只有 Agent 不够
很多人第一次用 Agent 工具时,最容易被它的执行力打动。你给它一个需求,它真的会开始分析、改代码、跑命令、修测试。这个体验很像突然多了一个不知疲倦的同事。
但如果项目稍微复杂一点,问题很快就会出现。
比如:
- 它不知道哪些目录是高风险目录
- 它不知道哪些配置不能随便改
- 它不知道哪些历史兼容逻辑不能动
- 它不知道哪些测试只是烟雾测试,不能代表真实安全
- 它不知道某个字段背后有前端、数据、运营流程的隐性依赖
这些不是单纯靠模型变聪明就能解决的。因为很多工程约束并不存在于代码表面,而存在于团队约定、历史事故和业务语义里。
没有 Harness 的 Agent,很容易变成一个“局部聪明、整体冒险”的执行者。它可能在某个函数里写得很好,却在系统边界上踩坑;它可能让单元测试通过,却破坏了部署配置;它可能把代码整理得更优雅,却删掉了某个看似多余、实际上承载兼容性的判断。
所以 Agent 越强,Harness 越重要。能力越大,越需要边界。
为什么只有 Harness 也不够
反过来说,Harness 也不能替代 Agent。
如果只有流程、规范、权限、检查清单,而没有一个能真正理解目标并执行任务的 Agent,那 Harness 就只是一个漂亮的框架。它可以告诉你应该怎么做,但不会替你完成工作。
这有点像传统工程里的 CI、代码规范和发布流程。它们很重要,但它们本身不生产功能。真正的实现仍然需要开发者去理解需求、写代码、修问题。
Agent 出现后,变化在于:执行者的一部分能力可以被模型承担了。它可以在 Harness 给定的边界里,完成更多具体动作。
所以两者的关系不是替代,而是配合:
- Agent 提供推理、生成和执行能力
- Harness 提供边界、流程和可信度
- Agent 让自动化真正动起来
- Harness 让自动化不至于乱跑
如果只有 Agent,系统会很有冲劲,但不够可靠;如果只有 Harness,系统会很规整,但没有生产力。两者合在一起,才接近“AI 工程化”真正需要的形态。
放到软件开发里,它们应该怎么配合
在软件开发场景里,我觉得比较健康的组合方式是:
目标输入 -> Harness 整理上下文和边界 -> Agent 拆解并执行 -> Harness 校验产物 -> 人做关键决策
这里最重要的不是把每一步都自动化,而是把每一步的责任分清楚。
比如一个需求进来,Harness 应该先明确:
- 这次任务允许改哪些目录
- 哪些文件必须先读
- 哪些命令可以执行
- 哪些操作需要人工确认
- 完成后必须留下哪些产物
- 哪些检查通过才算结束
然后 Agent 再在这个边界里工作。它可以写 proposal,可以改代码,可以跑测试,可以根据错误日志修复。但它不能随意越过边界,也不能把高风险动作当成普通步骤。
这就是 Harness 的价值:它把“希望 Agent 自觉”变成“系统默认约束”。
真正难的是把隐性规则写出来
从这个角度看,Harness 最难的部分其实不是工具,而是规则。
很多团队缺的不是 Agent,而是还没把自己的工程规则讲清楚。
哪些地方不能动?哪些历史逻辑有坑?哪些命令危险?哪些测试必须跑?哪些输出需要人工 review?哪些变更必须先写设计?这些东西如果只存在于老员工脑子里,Agent 就很难稳定工作。
所以建设 Harness 的过程,本质上也是一次工程知识显性化的过程。
你不是为了 AI 去写文档,而是借 AI 的出现,倒逼团队把原来靠口口相传维持的规则沉淀下来。沉淀得越清楚,Agent 就越能可靠地工作;沉淀得越模糊,Agent 就越容易在“看起来合理”的地方犯错。
这也是为什么我越来越觉得,AI 工程化并不是单纯挑一个更强的模型,而是重建一套能让模型稳定发挥作用的工程环境。
我的判断:未来拼的不是更自由的 Agent,而是更好的 Harness
未来 Agent 一定会越来越强。它会更会写代码,更会理解上下文,更会调用工具,也更会长任务规划。
但在真实工程里,决定它能不能大规模使用的,未必只是模型能力,而是 Harness 能不能跟上。
因为企业和团队真正关心的,不是 AI 能不能完成一次漂亮演示,而是它能不能在真实系统里反复工作、稳定交付、出错可控、过程可追溯。
所以我对 Agent 和 Harness 的关系有一个很简单的判断:
Agent 决定 AI 能做多少事,Harness 决定这些事能不能被信任。
一个成熟的 AI 工程体系,不会只是堆更强的 Agent,而会把 Agent 放进一套越来越清晰的 Harness 里。让它有上下文,有权限边界,有检查点,有记录,也有人在关键位置接住它。
真正有价值的不是让 AI 无限制地自由行动,而是让它在一条足够清楚、足够安全、足够可复用的工程轨道上,把能力稳定释放出来。
这可能才是 Agent 从玩具走向生产力工具时,必须跨过去的一道门槛。