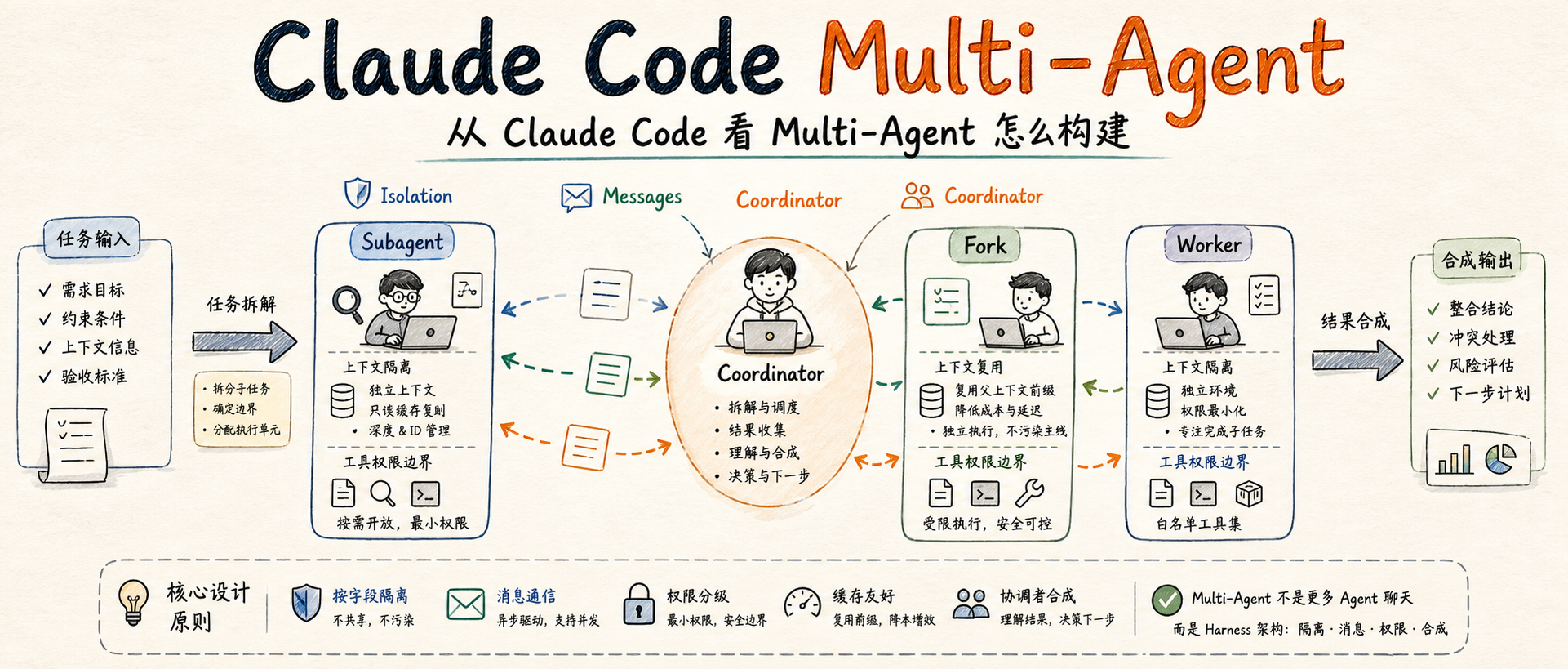
最近读到小林coding那篇关于 Claude Code 多 Agent 实现机制 的文章。原文讲了三个关键机制:常规 Subagent、Fork Subagent 和 Coordinator 模式。
我读完之后更关心的是另一个问题:如果我们自己要构建一个 Multi-Agent 系统,应该从哪里下手?
我的结论是:Multi-Agent 不是“多放几个 Agent 互相聊天”,而是 Harness 在运行时创建多个隔离的执行单元,并用消息、权限和协调者把它们收敛起来。
先别急着拆角色
很多人第一次设计 Multi-Agent,容易先画一张组织架构图:
- Planner 负责规划
- Researcher 负责调研
- Coder 负责实现
- Reviewer 负责审查
- Manager 负责协调
这个图看起来很舒服,因为它像一个真实软件团队。但模型不是人,Agent 之间也不是坐在同一个会议室里的同事。每多拆一个 Agent,就多一次 prompt、工具说明、上下文序列化、结果压缩和重新理解。
所以 Multi-Agent 的第一原则不是“角色越细越好”,而是先问:
这个任务有没有必要被隔离出去?
如果一个子任务会产生大量中间信息,但最终只需要一个稳定结论,那它适合交给 Subagent。比如调研一批文件、审查某个模块、比较几种方案、做一次只读安全检查。
如果一个任务本身很短,输入清楚、步骤明确、结果容易验证,硬拆成多个 Agent 反而是在制造交接成本。
第一层:常规 Subagent,解决局部隔离
常规 Subagent 是最基础、也最容易落地的一层。
它的价值不是“多一个人干活”,而是把一段局部探索放到独立上下文里执行。主 Agent 只需要给它一个明确任务,等它跑完后接收压缩后的结果。
这个设计能解决两个问题。
第一,保护主上下文。一个代码调研任务可能会读几十个文件、搜索很多次、形成大量中间判断。如果这些过程全塞进主会话,后续每一步都要背着这些历史继续跑。把它交给 Subagent,主 Agent 只拿到最后的发现和建议。
第二,保护任务边界。Subagent 可以拿到一套更窄的工具,比如只读文件、搜索代码、运行有限命令。它不需要拥有主 Agent 的全部权限,也不应该随意派生新的子任务或直接打断用户。
所以构建常规 Subagent 时,我会先定义四件事:
- 输入:它需要知道什么上下文
- 工具:它允许调用哪些能力
- 输出:它必须返回什么格式的结果
- 生命周期:什么时候结束,失败时怎么报告
这四件事比“给它起什么角色名”重要得多。
第二层:上下文隔离不是全共享,也不是全清空
多 Agent 最容易踩坑的地方,是上下文。
把父 Agent 的上下文完整共享给子 Agent,看起来最省事,但会污染状态。比如父 Agent 读文件读到某一段,子 Agent 接着读了后面一段,如果两边共享同一个读取缓存,父 Agent 后续可能误以为自己已经读过那些内容。
反过来,给子 Agent 一个完全空的新上下文也不行。它可能不知道当前任务的中止信号、权限边界、后台任务登记方式,也可能失去必要的运行环境。
更稳的做法是按字段决定:
- 只读缓存可以复制一份,避免互相污染
- 全局 UI 或主任务状态不让子 Agent 写
- 必要的后台任务登记通路要保留,方便回收
- 每个 Agent 都要有独立 ID 和深度信息,防止无限嵌套
这背后的判断很朴素:每一项状态都要问一句,子 Agent 拿它是为了完成任务,还是可能影响父 Agent 的判断?
只有按这个粒度做隔离,Multi-Agent 才不会变成一团共享状态。
第三层:通信走消息,而不是等函数返回
如果父 Agent 调一个函数,然后同步等待子 Agent 返回,这不是真正可用的 Multi-Agent。
因为子任务可能跑几分钟。父 Agent 不能在这几分钟里完全失去响应能力,也不能因为派了多个子任务就把主线程堵死。
更好的结构是消息驱动:
- 父 Agent 给子 Agent 发任务消息
- 子 Agent 在自己的循环里处理消息
- 任务完成后,子 Agent 把结果作为事件或消息交回父 Agent
- 父 Agent 根据到达顺序继续合成和决策
这让 Agent 之间的关系从“调用与返回”变成“投递与通知”。看起来只是通信方式变化,但它决定了系统能不能并发、能不能恢复、能不能在任务完成后继续唤醒某个旧 Agent。
如果一个 Multi-Agent 系统只能靠同步调用串起来,那它本质上还是单 Agent 的长链路,只是中间多了几个名字。
第四层:Fork Subagent,解决成本和延迟
Fork Subagent 的思路很有意思。它不是为了专业分工,而是为了在某些场景里复用父 Agent 的上下文前缀。
常规 Subagent 往往有自己的 system prompt 和工具说明。每派一次,LLM 都要重新处理一大段前缀。对于真实产品来说,这不是小事,因为成本和首 token 延迟会被放大。
Fork 的适用场景更像“从当前主线分出一个分身去做旁路任务”。它继承父 Agent 的大部分上下文,但不污染父 Agent 的主循环。
适合 Fork 的任务通常有几个特征:
- 它强依赖当前会话已有上下文
- 它只是短暂探索一条支线
- 它不需要独立的专业 prompt
- 它的结果可以很快回到主线
比如生成一次中间总结、基于当前上下文尝试另一个表达、为即将提交的改动整理说明。这类任务如果重新启动一个完全独立的 Subagent,反而浪费。
所以 Fork 不是常规 Subagent 的替代品。常规 Subagent 解决隔离和专业化,Fork 解决上下文复用和低成本旁路探索。
第五层:Coordinator,只在任务真的需要并行时出现
Coordinator 模式是最像“多 Agent 系统”的部分,但它也最不应该被滥用。
在这个模式里,主 Agent 不再是全能执行者,而是变成协调者。它主要做三件事:
- 拆任务并派发 worker
- 收集 worker 的结果
- 自己理解结果,再合成下一步决策
注意第三点最关键。协调者不能只是传话筒。如果它只是把 A worker 的发现转给 B worker,再把 B worker 的结果转给用户,那系统只是多了一层低质量中转。
真正有价值的 Coordinator 必须亲自合成。比如先并行派几个 worker 调研不同模块,等结果回来后,协调者自己读懂差异,写出清晰实现规格,再派实现 worker。到了验证阶段,最好再派新的 worker 做检查,而不是让刚写完代码的 worker 自证清白。
这套模式适合什么场景?
- 大规模代码迁移
- 多模块并行调研
- 复杂方案评估
- 长链路工程任务
- 需要调研、实现、验证分阶段推进的任务
如果只是修一个小 bug,Coordinator 只会让系统变慢。它的价值来自并行和合成,而不是来自“看起来更像团队”。
自己构建 Multi-Agent 时,可以从这张清单开始
我会把 Multi-Agent 的构建顺序压缩成一张工程清单。
第一,先定义主线。
主 Agent 必须掌握任务目标、用户对话权和最终决策权。不要让子 Agent 直接越过主线和用户交互,也不要让它随便改变全局计划。
第二,定义子任务边界。
每个子 Agent 都应该有明确输入、明确输出和明确退出条件。不要派一个“你自己看看吧”的 Agent,它会把复杂度原样带回来。
第三,做工具权限分级。
只读调研 Agent 不需要写文件权限;验证 Agent 不需要派生新 Agent;后台 Agent 不应该主动问用户问题。工具不是越多越好,越窄越可控。
第四,做上下文字段隔离。
哪些状态复制,哪些状态共享,哪些状态屏蔽,哪些状态新建,要逐项判断。粗暴地全共享或全清空,都会在复杂任务里暴露问题。
第五,通信消息化。
父子 Agent 之间不要依赖同步函数返回。让任务、进度、结果都变成可记录、可恢复、可排队的消息。
第六,结果必须被合成,而不是拼接。
多个 Agent 给出的结果通常会有冲突、重复和盲点。主 Agent 或 Coordinator 要做判断:哪些结论可信,哪些需要验证,哪些应该丢弃。
第七,给并发加边界。
并发是 Multi-Agent 的收益来源,也是失控来源。要限制同时运行数量、嵌套深度、最长执行时间和失败重试策略。
最后:Multi-Agent 是 Harness 能力,不是 prompt 魔法
这篇文章给我的最大提醒是,Multi-Agent 的关键不在 prompt 里,而在 Harness 里。
Prompt 可以告诉一个 Agent “你是 Reviewer”,但 Harness 才能决定它能不能写文件、能不能问用户、能不能派生新任务、能不能污染主上下文、失败后怎么回收、完成后怎么把结果交回主线。
如果没有这些工程边界,多 Agent 只是多个模型轮流说话。
如果边界设计得好,Multi-Agent 才会变成一种很实用的能力:把复杂任务拆成可隔离、可并发、可验证的执行单元,然后再收敛成一个明确结果。
所以我现在更愿意这样理解它:
Agent 负责做事,Harness 负责让多个 Agent 在正确的边界里做事。
真正的 Multi-Agent,不是让系统看起来更热闹,而是让复杂任务在隔离、并发和合成之间找到平衡。