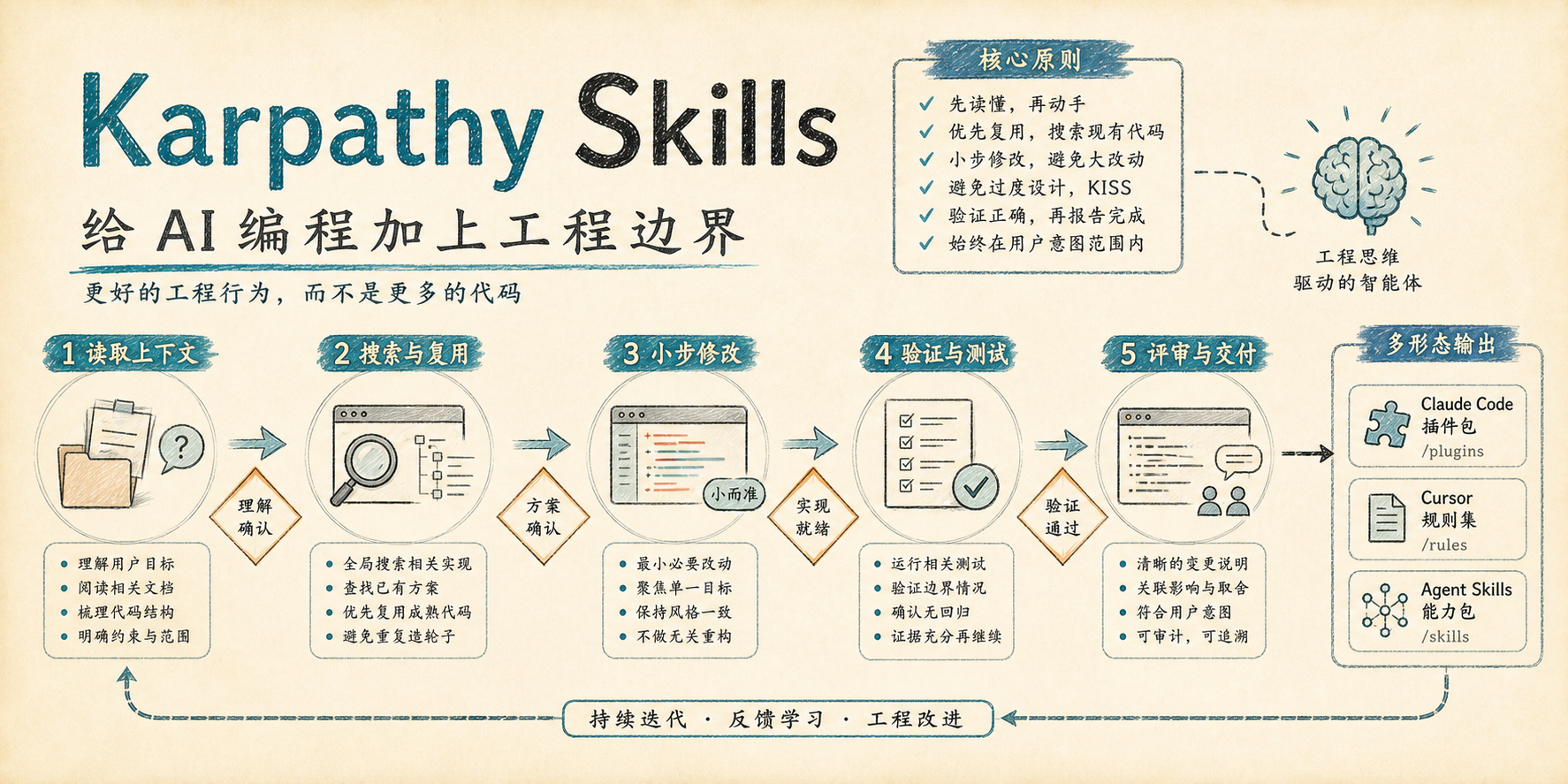
最近看到一个很有意思的仓库:multica-ai/andrej-karpathy-skills。它看起来不像传统意义上的代码库,也不像一个可以直接运行的工具。里面没有复杂框架,没有业务代码,也没有什么炫目的工程实现。它更像是一组给 AI 编程助手准备的“行为准则包”。
但也正因为这样,我反而觉得它挺值得单独写一写。
很多 AI 编程工具现在都在强调更强的模型、更大的上下文、更快的代码生成。但这个仓库关注的方向刚好相反:它不是继续放大 AI 的生成能力,而是试图约束 AI 在工程现场里的行为方式。说得直白一点,它解决的不是“AI 能不能写代码”,而是“AI 写代码时能不能别太自信、别乱扩张、别跳过验证”。
这个仓库到底是做什么的
从仓库结构上看,它主要做了几件事。
第一,它把一组 Andrej Karpathy 风格的 AI 编程原则整理成可复用文本,比如 CLAUDE.md、CURSOR.md、Cursor rules,以及 skills/karpathy-guidelines/SKILL.md。
第二,它把这些原则包装成不同工具能消费的形式:
- Claude Code 可以通过 plugin 或
CLAUDE.md使用 - Cursor 可以通过
.cursor/rules使用 - 其它支持 Skill 概念的 Agent 可以通过
SKILL.md使用
第三,它并不试图替你实现某个具体功能,而是给 AI 编程助手加上一组工作习惯:
- 先理解上下文
- 先找已有实现
- 小步修改
- 避免过度工程
- 不要擅自扩展需求
- 写完要验证
- 不要为了兼容假想场景而把代码搞复杂
所以它的作用不是“增强某个项目”,而是约束 AI 参与任何项目时的默认姿势。
这点很关键。因为现在很多 AI coding 翻车,并不是模型不会写代码,而是它太急着写代码。
它解决的核心问题:AI 的问题不是不会做,而是太容易“顺手多做”
人类工程师写代码时,真正难的往往不是把某个函数补出来,而是知道什么时候不该补、什么时候该停、什么时候应该先问、什么时候应该先查已有约定。
AI 在这件事上特别容易出问题。
比如一个需求只是修一个边界 bug,它可能顺手重构半个模块;一个测试失败本来是 mock 配错了,它可能开始改业务逻辑;一个项目已经有现成工具函数,它偏偏重新写一套;一个兼容性场景根本不存在,它却先设计一堆抽象层。
这些问题的共同点是:单独看每一步都好像“很努力”,但放到工程里反而是风险。
所以这个仓库真正想解决的问题,是 AI 编程里的几个高频失控点:
- 过早开始实现
- 没有检索已有代码
- 把局部问题扩大成系统改造
- 为不存在的需求设计复杂抽象
- 修改范围超过用户意图
- 没有跑验证就宣称完成
- 在不确定时假装确定
这其实很像把资深工程师的 code review 直觉,前置成 Agent 的行为约束。
它不教 AI 某个框架怎么用,而是教 AI 在进入任何框架之前,先像一个更谨慎的工程师那样工作。
关键思想一:AI 编程首先是上下文管理,不是代码生成
这个仓库里最重要的思想,我理解是:先读,再写。
这句话听起来简单,但对 AI Agent 来说非常关键。因为模型天然擅长生成,它看到一个问题,很容易直接进入“我来写答案”的状态。但软件工程不是考试题,很多时候答案藏在已有代码、历史约定、测试结构、命名习惯和项目边界里。
一个不读上下文的 AI,写得越快,越容易制造隐性成本。
所以这套准则会反复强调:
- 先搜索已有实现
- 先理解项目模式
- 先确认问题范围
- 先看相关测试
- 先判断改动是否真的必要
这背后的逻辑是:AI 的生成能力已经足够强,真正稀缺的是约束生成的上下文。
我觉得这是今天 AI 编程里非常值得重视的一点。很多团队引入 AI 后,第一反应是“怎么让它写更多代码”。但更成熟的问法应该是:怎么让它在写代码之前拿到正确上下文,怎么让它知道哪些地方不能乱碰,怎么让它知道当前项目已经有自己的惯性。
关键思想二:小步修改比大范围重构更适合 Agent
这个仓库的另一个明显倾向,是鼓励 AI 做小而明确的改动。
这和人类工程师的经验是一致的。越是自动化参与的流程,越应该让改动范围可控。因为一旦 AI 同时改很多东西,后面就很难分清:
- 哪个改动是为了解决原问题
- 哪个改动只是顺手清理
- 哪个改动引入了新的行为变化
- 哪个测试失败是预期内的
所以它强调避免无关重构、避免额外抽象、避免大范围格式化。这些约束看起来有点保守,但在 AI coding 场景里特别重要。
因为 AI 最大的问题不是不会补代码,而是补得太顺。
一个好的 Agent 工作流,应该让每一次改动都能回答三个问题:
- 为什么改
- 改了哪里
- 怎么证明它是对的
如果回答不了,那就说明这次改动已经超出了工程可审计的范围。
关键思想三:不要为假想需求提前设计复杂系统
我很喜欢这个仓库隐含的一种反过度工程倾向。
传统开发里,过度工程本来就很常见。AI 加进来之后,这个问题会被放大。因为模型特别擅长把一个小问题包装成一个看起来很完整的方案:配置层、抽象层、适配器、扩展点、兼容策略、未来规划,一套下来非常像那么回事。
问题是,真实工程里很多复杂度并不是资产,而是负债。
如果当前需求只是修一个具体问题,那最好的实现可能就是一个清晰的小改动,而不是提前构建一个“未来可扩展架构”。这个仓库的准则,本质上是在提醒 AI:
不要为了展示能力而增加复杂度。
这对 Agent 特别重要。因为 Agent 没有长期维护成本的直觉。它不会真的在三个月后被自己写的抽象折磨,也不会参加后续的线上事故复盘。它更容易被“看起来完整”的方案吸引。
所以我们需要把“简单优先”“按需设计”“不要扩大范围”这些原则写成明确规则,让 AI 每次动手前都被提醒一次。
关键思想四:验证不是收尾动作,而是完成定义的一部分
另一个很实用的点,是它把验证放在很重要的位置。
AI 编程里最危险的一句话是:“应该可以了。”
真实工程里,完成不是模型觉得逻辑通了,也不是代码看起来漂亮,而是有证据说明它符合预期。这个证据可以是测试、类型检查、lint、构建、手工验证步骤,也可以是对限制条件的明确说明。
所以这类规则会要求 Agent 写完之后去验证,而不是只给一个自然语言总结。
这件事听起来像流程细节,但其实是 AI 工程化里最核心的边界之一:
- 没有验证,AI 只是在生成
- 有了验证,AI 才开始接近工程交付
当然,验证也不是越重越好。不同任务需要不同验证强度。小文案改动不需要跑全量测试,核心业务逻辑改动就不能只看 diff。关键是 Agent 必须意识到:输出代码只是过程,证明代码可用才是结果。
它是怎么实现的:用“可安装的规则”替代临时提示词
从实现方式看,这个仓库很朴素,但方向很对。
它没有写一个复杂运行时,而是把原则拆成多种 AI 工具能读取的文件格式:
CLAUDE.md:给 Claude Code 读取的项目级指令.claude-plugin/plugin.json:把规则包装成 Claude Code plugin.cursor/rules:给 Cursor 的规则文件skills/karpathy-guidelines/SKILL.md:给支持 Skill 的 Agent 使用CURSOR.md:给手动配置 Cursor 的说明
这种实现方式的好处是低耦合。它不是要求你换一套开发平台,而是把同一套工程原则翻译成不同工具能接受的入口。
换句话说,它做的不是“发明新 Agent”,而是把一组高质量工作习惯变成可迁移、可安装、可复用的配置。
这也是我觉得它有价值的地方。很多团队现在的问题并不是不知道某条原则,而是这些原则只存在于人的口头提醒里。比如“先看现有代码”“不要乱重构”“改完跑测试”,大家都懂,但 AI 不一定懂,每次对话也不一定记得。
一旦这些东西被固化成 Skill 或规则文件,团队就不用每次都重新提醒 Agent。规则从“临时 prompt”变成了“默认工作环境”。
它的价值不在 Karpathy 本人,而在“把人的工程直觉显性化”
这个仓库借了 Andrej Karpathy 的名字,容易让人以为重点是某种个人方法论崇拜。但我觉得真正重要的不是名字,而是它代表的一类趋势:
我们正在把优秀工程师的隐性习惯,转写成 AI 可以执行的显性规则。
这件事会越来越重要。
因为 AI 编程工具越强,单纯“会写代码”的门槛越低,流程约束、验证习惯、上下文管理和边界意识就越值钱。以后团队之间的差距,可能不只是“谁用了更强的模型”,而是“谁把自己的工程判断沉淀成了更好的 Agent 环境”。
从这个角度看,andrej-karpathy-skills 不是一个终点,而是一个很小但很典型的样本。它提醒我们:AI coding 的下一阶段,不应该只卷模型能力,也应该卷工作方式。
我的判断:这类仓库会成为 AI 工程化里的基础设施
如果把它当成一个普通开源项目看,它确实很小。它没有复杂架构,也没有什么技术炫技。
但如果把它放到 AI 工程化的视角里,它的意义就清楚了:它是在给 Agent 建立默认行为边界。
未来每个成熟团队,很可能都会有类似的东西:
- 项目的
AGENTS.md - 团队自己的编码准则 Skill
- 针对高风险目录的权限规则
- 代码评审和测试策略的提示约束
- 面向不同工具的规则适配层
这些东西不会替代工程师,但会把工程师反复强调的基本功,前置到 AI 开始工作之前。
所以我对这个仓库的理解是:
它不是为了让 AI 更像一个代码生成器,而是为了让 AI 更像一个受过工程训练的协作者。
这可能也是 AI 编程真正进入生产流程之前,最需要补上的一块。