随机森林这个名字,第一次听起来很像一个很硬的机器学习概念。森林、随机、算法,几个词放在一起,很容易让人以为它背后一定有一大堆数学公式。
但如果用通俗的话讲,随机森林其实没有那么神秘。它做的事情很像我们生活里经常用的一种决策方式:
不要只听一个人的意见,多问几个人,然后看多数人怎么选。
为了把这件事讲清楚,我们可以用一个很生活化的问题来类比:周末晚上到底去哪儿吃饭?
先从一棵决策树说起
在理解随机森林之前,先要理解什么是决策树。
决策树可以理解成一个“单线思维但逻辑很清楚的朋友”。你问他:“今晚吃什么?”他不会给你讲一堆复杂理由,而是按一串条件一步一步判断。
比如他的脑子里可能有这样一棵树:
- 今天下雨吗?
- 如果下雨,就去吃火锅
- 如果没下雨,再看预算
- 预算超过 100 元吗?
- 如果超过,就去吃日料
- 如果没超过,就去吃麻辣烫
这就是决策树的基本样子:每一步都问一个问题,根据答案走向下一步,最后得到一个结果。
它的优点很明显:简单、直观、容易解释。你能很清楚地看到它为什么做出这个判断。
但它的缺点也很明显:太容易钻牛角尖。
比如今天虽然没下雨、预算也够,但你感冒了,其实不想吃日料。可这棵树只看“天气”和“预算”,没把“身体状态”考虑进去,于是还是很坚定地推荐日料。
这就是单棵决策树的问题:它很容易被自己看到的那部分信息带偏。在机器学习里,这类现象经常会表现成过拟合。
所谓过拟合,简单说就是:模型把过去的数据记得太死,结果一到新情况就不灵了。
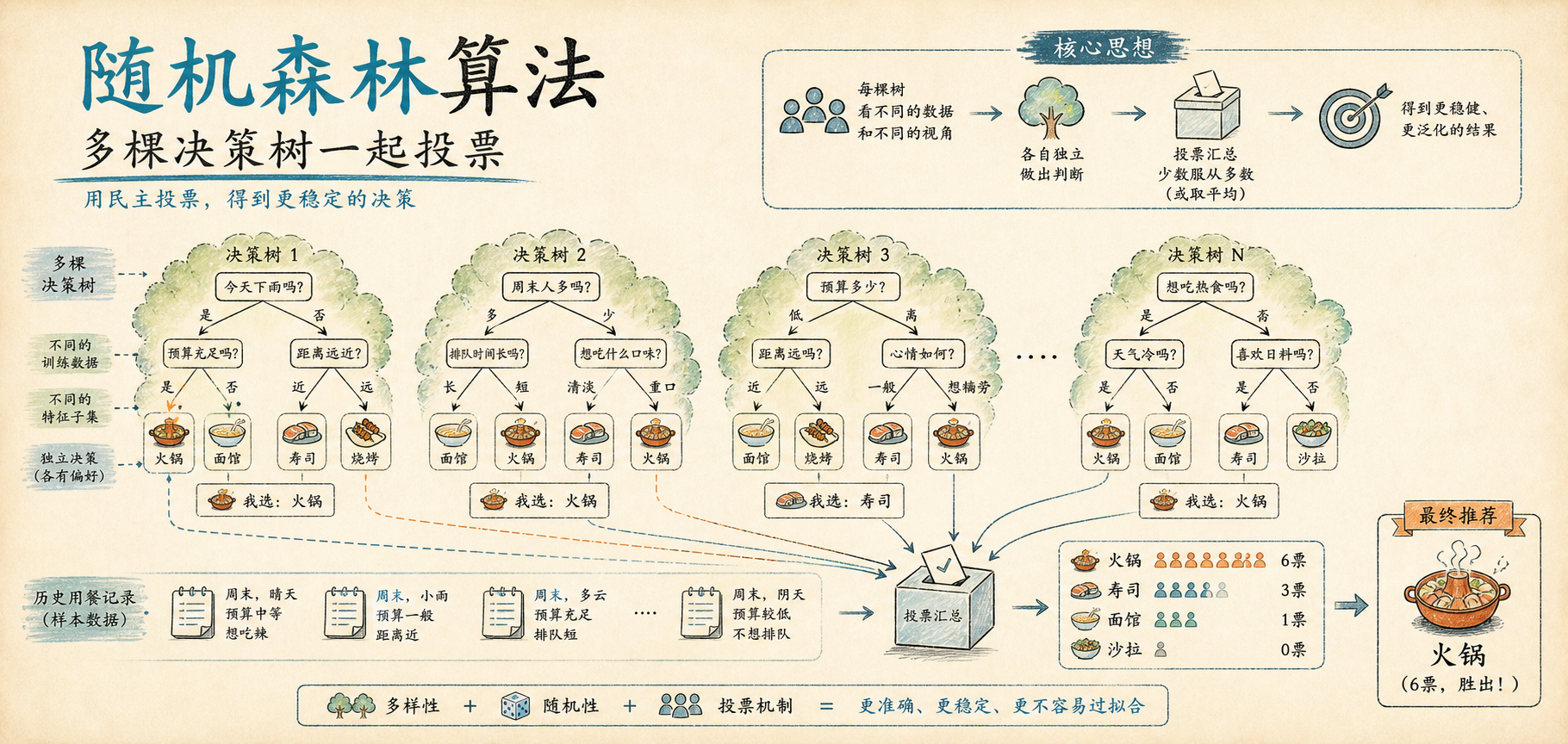
随机森林:别只问一个朋友,拉个群一起投票
为了避免一个朋友太片面,你决定多问几个人。
你拉了一个 100 人的群,每个人都帮你判断“今晚吃什么”。这 100 个人,每个人都像一棵决策树。有人特别看重天气,有人特别看重预算,有人更在意距离,有人更怕排队,有人只关心今天心情好不好。
这 100 棵决策树放在一起,就是“森林”。
但这里还有一个问题:如果这 100 个人背景完全一样、看过的信息完全一样、判断标准也完全一样,那他们虽然人数很多,本质上还是同一个人说了 100 遍。
这样的“森林”并不会更聪明。
所以随机森林真正厉害的地方,不只是树多,而是让这些树彼此之间有差异。它会刻意制造多样性,让每棵树都从略微不同的角度看问题。
这就是“随机”两个字的来源。
第一种随机:每棵树看到的数据不完全一样
假设你有很多过去吃饭的记录:
- 哪天吃了什么
- 当天天气如何
- 预算多少
- 心情怎么样
- 距离远不远
- 最后满意不满意
如果你把全部记录原封不动地发给每个人,他们学到的东西可能会很相似。
随机森林不会这么做。它会给每棵树随机抽一批历史记录,而且是“有放回地抽样”。
“有放回”听起来有点抽象,可以想象成这样:你从一堆就餐记录里抽一张,看完之后又放回去,再继续抽下一张。这样同一条记录可能被抽到多次,也可能有些记录完全没被抽到。
第一个朋友可能看到的是一批历史记录,第二个朋友看到的是另一批,第三个朋友又不一样。它们学到的口味历史自然就会有差异。
这个过程在机器学习里叫 Bootstrap,也叫自助法抽样。
它的目的不是让数据变多,而是让每棵树看到的训练材料略有不同。这样训练出来的树才不会都长成一个样子。
第二种随机:每棵树考虑的因素也不完全一样
除了数据随机,随机森林还有一个更关键的随机:特征随机。
还是吃饭这个例子。假设你有很多可参考因素:
- 天气
- 预算
- 距离
- 心情
- 排队时间
- 卫生状况
- 是否想吃辣
- 是否适合聊天
如果每棵树每次分叉时都能从所有因素里挑最优的那个,那么很多树可能都会优先选择同一个强特征。结果是大家虽然看了不同数据,但判断方式还是很像。
随机森林会故意限制它们:每棵树在做判断时,只能从一部分随机特征里挑。
比如:
- 第一棵树只能看天气、预算、距离
- 第二棵树只能看心情、排队时间、是否想吃辣
- 第三棵树只能看卫生状况、距离、是否适合聊天
这样一来,每棵树就会被迫从不同角度思考问题。
这点非常重要。因为一个群体真正有价值,不是人数多,而是视角不同。
随机森林靠“样本随机”和“特征随机”这两件事,制造出一批差异足够大的决策树。然后再让它们一起投票。
最后怎么得出结果:分类投票,回归取平均
当 100 棵树都训练好之后,新的问题来了:今天晚上到底吃什么?
每棵树都会给一个答案。
比如:
- 30 棵树建议吃日料
- 60 棵树建议吃火锅
- 10 棵树建议吃麻辣烫
如果这是一个分类问题,随机森林就会采用投票机制。谁票数最多,谁就是最终答案。
所以它会说:今晚吃火锅。
这就是随机森林做分类任务的方式。
但如果问题不是“选哪个类别”,而是预测一个数字,比如房价、气温、销量,那它就不会投票,而是让每棵树都给出一个数字,然后求平均值。
比如 100 棵树分别预测明天的气温,最后把这些预测结果平均一下,得到最终预测。
所以可以简单记:
- 分类问题:多数投票
- 回归问题:结果平均
为什么随机森林通常比单棵树靠谱
随机森林最核心的优势,是它用群体判断抵消单个模型的偏见。
单棵决策树很容易被局部数据带偏。它可能因为某几条特殊记录,就学到一个很极端的规则。比如过去几次下雨你都吃火锅,它就可能过度相信“下雨一定吃火锅”。
但在随机森林里,不同树看到的数据不同、考虑的因素不同。某一棵树的偏见,通常会被其它树抵消掉。
这就像你问 100 个朋友。某个人可能特别爱吃火锅,所以什么情况都推荐火锅;另一个人可能特别讨厌排队,所以一看到热门餐厅就否决。但只要人数足够多、视角足够多,最终结果往往会比单个人更稳定。
这也是随机森林不容易过拟合的原因之一。
它不是要求每棵树都完美,而是让很多棵不完美的树组合起来,得到一个更稳的整体判断。
它为什么“皮实”
随机森林还有一个很大的优点:鲁棒性比较高。
所谓鲁棒性,可以理解成“不太容易被小问题搞崩”。
如果其中几棵树判断错了,问题不大。因为最终结果不是由一棵树决定的,而是由整个森林决定的。
如果数据里有一些噪声,问题也不一定很大。因为噪声可能只影响一部分树,不会轻易控制整个森林。
如果某些特征不是特别可靠,随机森林也相对能扛。因为每棵树用到的特征组合不一样,单个特征的坏影响会被分散。
这也是为什么随机森林在很多传统机器学习任务里很受欢迎。它不一定是最酷、最新的算法,但经常是一个很稳的基线模型。
在很多业务问题里,先跑一个随机森林,往往能很快得到一个还不错的结果,而且不需要像深度学习那样准备特别复杂的训练流程。
但随机森林也不是万能的
当然,随机森林并不是没有缺点。
第一,它不如单棵决策树那么容易解释。
一棵树的判断路径很好看懂:从根节点一路走到叶子节点,逻辑非常清楚。但随机森林里有几十棵、几百棵树,最终结果来自整体投票。你可以大概看出哪些特征重要,但很难像单棵树那样解释每一步。
第二,它的模型体积和计算成本更高。
一棵树很轻,几百棵树自然就更重。数据量大、树很多时,训练和预测都会更耗资源。
第三,它对某些结构化之外的问题并不一定是最佳选择。
比如图像、语音、自然语言这类复杂感知任务,深度学习通常更适合。但在表格数据、业务预测、风控、分类、回归这些场景里,随机森林依然很有生命力。
所以对它最好的理解不是“万能模型”,而是“稳健、好用、容易上手的传统机器学习强基线”。
一句话总结随机森林
如果只用一句话总结随机森林,我会这么说:
随机森林就是训练很多棵各有偏见但视角不同的决策树,再让它们通过投票或平均,得到一个比单棵树更稳的结果。
它的关键不在于某一棵树特别聪明,而在于整个群体足够多样。
这也是它名字里“森林”的意义:一棵树可能长歪,一片森林通常更稳。
回到开头那个吃饭问题,如果你只问一个朋友,很可能被他的偏好带偏;但如果你问一群背景不同、关注点不同、掌握信息也略有不同的人,最后投出来的结果通常会更靠谱。
随机森林做的,就是把这种生活里的朴素智慧,变成一套机器学习算法。
它并不神秘。它只是很认真地相信一件事:
不要迷信单一判断,让足够多元的意见一起说话。