昨天看到 Satya Nadella 在 X 上发的一篇长文:A frontier without an ecosystem is not stable。这篇文章表面上是在谈 AI 时代企业应该如何构建自己的能力,但我觉得它真正有价值的地方,不是又提出了一个关于大模型的判断,而是把一个更底层的问题说清楚了:
AI 时代,公司的核心资产不会只是“用了哪个模型”,而是能不能把自己的经验、流程、判断和组织记忆,变成一套持续变强的学习系统。
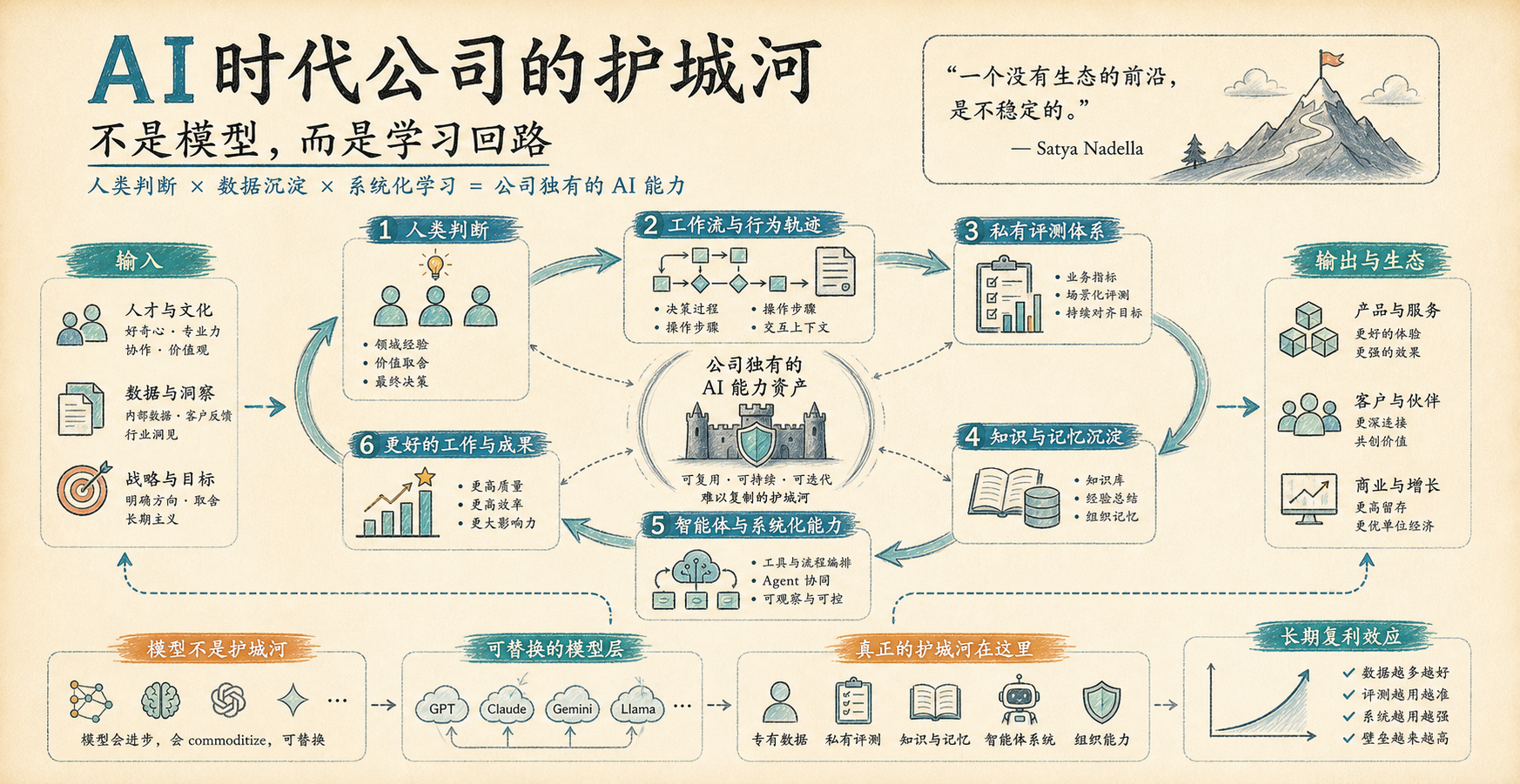
这件事如果说得更直白一点,就是:未来企业之间的差距,不只取决于谁接入了更强的模型,而取决于谁能把模型放进自己的业务循环里,让每一次使用都留下可复用的知识、信号和改进。
这篇文章到底在讲什么
Satya 这篇文章的核心判断是:AI 带来的变化,不是传统意义上的又一次软件工具升级。
过去几十年,企业用数字系统提升人的效率。比如 ERP、CRM、协同办公、数据平台,本质上都是把人的工作流程数字化,让人做得更快、更可见、更可管理。
但这一次不太一样。
AI 不只是帮人记录、查询、自动化,而是开始和人的认知过程发生循环。人提出目标、做判断、积累经验;AI 执行任务、总结模式、生成反馈;然后这些反馈又反过来帮助组织学得更快。
这就让企业的核心问题发生了变化。
以前企业要问的是:
- 我能不能买到更好的软件
- 我能不能把流程数字化
- 我能不能让员工更高效
现在更关键的问题变成:
- 我的业务知识能不能被 AI 系统吸收
- 我的工作流能不能越用越好
- 我的组织经验能不能沉淀成可复用能力
- 我的核心判断会不会被通用模型快速商品化
这也是文章标题里“frontier ecosystem”的意思。只追求 frontier model,也就是最前沿的模型,本身是不够稳定的。真正稳定的 AI 未来,应该是一个生态:每家公司、每个行业、每个国家,都能在模型之上建立自己的学习能力,而不是把全部价值交给少数几个通用模型。
Human Capital 和 Token Capital:一个很重要的区分
文章里有一个概念很值得展开:human capital 和 token capital。
Human capital 很好理解,就是公司里人的知识、判断、关系、创造力、模式识别能力。它不是简历上的技能列表,而是人长期在业务里积累出来的真实经验。
比如:
- 哪类客户其实最难服务
- 哪个指标看起来健康但其实有误导性
- 哪个流程表面高效但长期会制造债务
- 哪个需求听起来合理但背后是假问题
- 哪些团队协作方式会让事情真正推进
这些东西很难完全写进标准文档里,但它们确实构成了公司的能力。
Token capital 则可以理解成公司自己构建和拥有的 AI 能力。这里的 token 不是币,而是 AI 系统处理、生成、学习和执行任务时消耗的计算表达单位。更准确地说,它代表企业把模型、数据、工作流、知识库、评估体系和反馈机制组合起来之后形成的智能资产。
这两个概念放在一起,文章的判断就很清楚了:
AI 能力越强,人的判断不是越不重要,而是越重要。
原因很简单。没有人的方向感,AI 只是算力在原地打转。模型可以生成很多东西,但它不知道哪些目标值得追,哪些模式真正重要,哪些结果对业务有意义。
所以未来企业真正要建设的,不是一个“替代人”的系统,而是一套让 human capital 和 token capital 互相复利的系统。
人的判断指导 AI,AI 的执行和反馈放大人的判断;人的经验被系统吸收,系统又把这些经验变成更多人可以使用的能力。
这才是重点。
真正的机会不是选模型,而是建立学习回路
很多公司现在谈 AI 落地,第一反应还是选模型。
用 GPT,还是 Claude?用 Gemini,还是开源模型?要不要私有化?要不要微调?这些问题当然重要,但它们可能不是最根本的问题。
Satya 的观点更接近另一个方向:真正的机会,是在模型之上建立学习回路。
这个学习回路至少包括几件事:
- 把业务工作流接入 AI 系统
- 把领域知识变成可查询、可调用、可更新的知识资产
- 用私有评估集衡量模型是否真的解决业务问题
- 用真实业务过程产生的反馈改进系统
- 让每一次任务执行都沉淀新的信号
这和“拿 AI 做一个工具”是两回事。
如果只是让 AI 帮你写一封邮件、总结一篇文档、生成一段代码,那它确实提高了单次效率。但任务结束之后,组织并没有变得更聪明。下一次遇到类似问题,还是从头再来。
学习回路的不同之处在于:每一次使用都会留下东西。
比如一次销售跟进,不只是生成一封邮件,而是沉淀客户反应、话术效果、行业差异和成交路径;一次代码生成,不只是完成一个功能,而是沉淀项目约定、测试策略、隐性架构规则和故障经验;一次客服处理,不只是回答用户,而是更新问题分类、产品缺陷和知识库。
当这些信号持续积累,企业就不只是“用了 AI”,而是在让 AI 系统承载自己的组织经验。
公司真正要保护的,是自己的隐性知识
这篇文章里还有一个很现实的担忧:如果所有价值都流向少数几个通用模型,企业和行业会被掏空。
这不是一个纯技术问题,而是经济结构问题。
如果所有公司的数据、流程、经验、判断,最后都被少数模型吸收,然后这些模型再把能力以标准化产品的形式卖回给所有人,那么长期看,企业自己的差异化会被削弱。
这有点像过去全球化里某些产业被外包掏空的过程。账面效率可能提高了,但本地能力、工艺经验、产业知识和就业结构被慢慢抽走。AI 时代如果处理不好,也可能出现类似问题:公司的知识不断被外部模型商品化,最后自己只剩下调用接口的能力。
所以企业必须回答一个问题:
我的哪些知识,必须留在自己的学习系统里?
这里的“留住”不是简单地把数据锁起来,而是要让这些知识在内部系统中持续发挥作用。
比如:
- 私有知识库保存机构记忆
- 私有 eval 衡量业务真实结果
- 私有工作流记录任务执行轨迹
- 私有反馈机制让系统越用越懂业务
- 私有 agent 系统把经验变成可复用动作
这才是企业在 AI 时代的主权问题。
不是“我有没有模型”,而是“我有没有自己的学习回路”。
为什么“可替换模型”很重要
文章里有一个判断我觉得特别关键:企业应该能替换通用模型,但不能丢掉自己积累出来的公司经验。
这句话背后其实是一个架构原则。
如果一家公司的 AI 能力完全绑定在某个模型上,那么模型一换,能力就断了。它积累的提示词、流程、知识、评估、反馈,可能都和那个模型强耦合。
这种系统看起来跑得很快,但不够稳。
更合理的架构应该是:
- 通用模型可以替换
- 企业知识库可以保留
- 工作流可以复用
- 评估体系可以持续
- 反馈数据可以继续积累
- agent 行为可以逐步优化
模型是底座,但公司自己的学习系统才是资产。
这也解释了为什么“只追逐最新模型”并不是长期战略。最新模型会变,价格会变,能力边界会变,供应商格局也会变。但企业自己的领域知识、流程经验和判断体系,如果能沉淀下来,就会形成更稳定的复利。
在这个意义上,AI 架构的重点不只是调用能力,而是解耦能力。
你要能使用最好的模型,也要能在模型变化时保住自己的组织记忆。
放到软件研发里,这件事其实很具体
这篇文章虽然讲的是企业,但我觉得放到软件研发里尤其有启发。
很多团队现在使用 AI coding,还是停留在“让模型多写点代码”的阶段。它当然有帮助,但如果没有学习回路,收益会很快碰到天花板。
一个真正有复利的研发 AI 系统,应该沉淀这些东西:
- 项目的架构约定
- 历史事故和踩坑记录
- 代码评审标准
- 测试策略
- 高风险目录和禁止操作
- 需求到实现的拆解模式
- 常见 bug 的诊断路径
- 团队对“好代码”的判断
这些东西如果只存在于资深工程师脑子里,AI 每次进入项目时都要重新猜。如果把它们整理成 AGENTS.md、Skill、评审脚本、私有知识库、项目级 eval,那 AI 就有机会越用越贴近团队。
这也是我最近越来越认同的一点:AI coding 的核心不是“生成代码”,而是“把团队的工程判断显性化”。
代码只是输出,判断才是资产。
一个团队如果能把判断沉淀到系统里,它用任何模型都会越来越强;反过来,如果所有经验都散落在聊天窗口里,再强的模型也只能带来一次性效率。
我的理解:企业 AI 化的终点不是自动化,而是组织学习速度
很多人谈 AI 时代的企业,容易落到“减少多少人”“替代多少岗位”“自动化多少任务”这些问题上。
这些当然会发生,但我觉得它们不是最值得关注的主线。
更重要的问题是:企业能不能学得更快。
能不能把一线经验快速变成系统能力?能不能把个体判断变成团队资产?能不能让每一次客户互动、每一次代码提交、每一次故障复盘都反哺 AI 系统?能不能让新人更快站到组织已有经验之上,而不是从零摸索?
如果可以,那么 AI 带来的就不是一次工具升级,而是组织学习速度的变化。
这也是 Satya 这篇文章最打动我的地方。它没有把 AI 描述成一个简单的替代机器,而是把它放进企业如何积累知识、放大判断、形成差异化的框架里。
所以如果用一句话总结我的理解:
AI 时代公司的护城河,不是拥有某个最强模型,而是拥有一套能把人的经验转化为系统能力、并且持续复利的学习回路。
模型会迭代,接口会变化,价格会下降。但一家公司的隐性知识、业务判断和组织学习方式,如果能被系统化沉淀下来,就会成为真正难以复制的东西。
这大概也是“frontier ecosystem”比“frontier model”更重要的原因。